


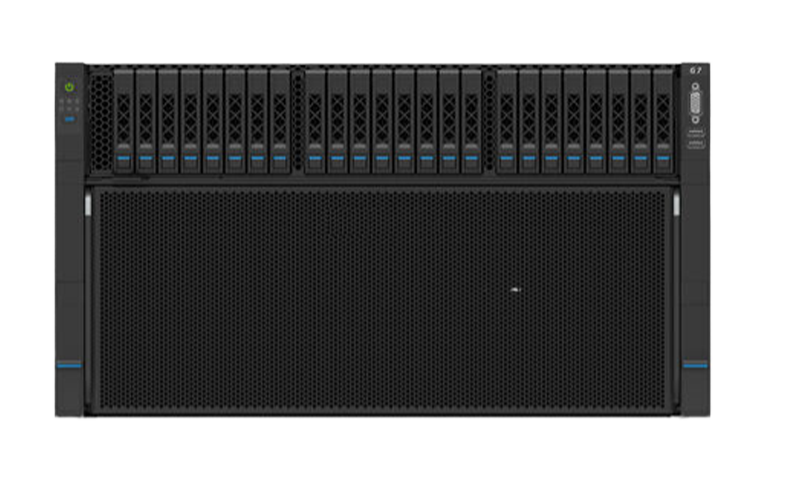

Powered by 8 NVIDIA latest GPUs in 6U, TDP up to 700W
2x 4th Gen Intel® Xeon® Scalable processors
16PFlops of industry-leading AI performance
H100 Transformer Engine delivers supercharged training speed for GPT large language models
Lightning-fast CPU-to-GPU interconnect bandwidth
Ultra-high scalable inter-node networking with up to 4.0 Tbps non-blocking bandwidth
Optimized cluster-level architecture with 8:8:2 ratio of GPU to compute network to storage network
Low air-cooled heat dissipation overhead and high power efficiency
54V, 12V separated power supply with N+N redundancy reducing power conversion loss
Direct liquid cooling design with over 80% cold plate coverage keeps PUE ≤1.15
Fully modular design and flexible configurations satisfy both on-premises and cloud deployment
Easily harness large-scale model training, such as GPT-3, MT-NLG, stable diffusion and Alphafold
Diversified SuperPod solutions accelerating the most cutting-edge innovation including AIGC, AI4Science and Metaverse



